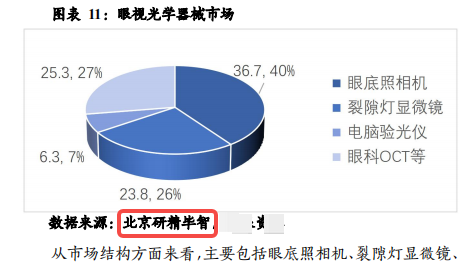
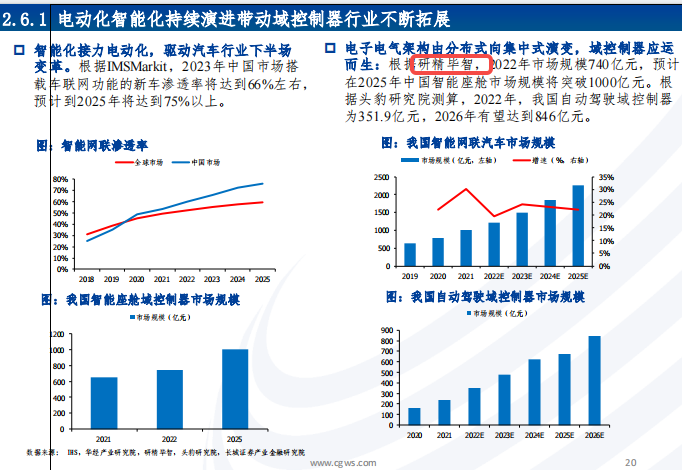
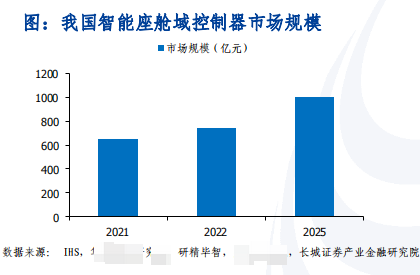
一、人工智能(基础层/技术层/应用层)
1、华为宣布“CANTIAN”引擎开源 携手共建数据库存储新生态
8月25日,在2023华为数据存储用户精英论坛上,华为正式宣布开源“CANTIAN”引擎,吸纳更多数据库生态伙伴,基于共享存储共同推动国产数据库生态体系发展,促进国产应用生态持续壮大,合作共赢数字化时代。据华为表示,这一引擎将坚定支持PG、MySQL开源社区以及相关商业数据库,同时增强存算分离和多读多写能力,推动国产数据库向多主架构升级。华为还将与数据库产业伙伴合作,共同打造“分布式架构+集中式体验”的解决方案,以替代Oracle的数据库存储。

2、澜舟科技正式发布百亿参数大模型“孟子 GPT-40 B”训练速度提升8.5倍中文能力突出已开启邀测
8月28日消息,国内大模型创企澜舟科技正式发布参数量400亿的孟子GPT-40B通用大模型、参数量70亿的孟子GPT-7B金融大模型,并推出基于孟子GPT大模型打造的会议内容分析平台澜舟智会。孟子GPT-40B通用大模型现已开启邀测,中文能力更加突出,并兼顾多语言能力,无论是聊英文还是其他语种,都有同步的整体提升,语料均来自网页、百科、社交媒体、新闻以及澜舟科技与合作伙伴的一些高质量中文开源数据集。
3、阿里云开源通义千问多模态大模型Qwen-VL
8月25日消息,阿里云今日推出了大规模视觉语言模型Qwen-VL,目前已经在ModeScope开源,据悉,Qwen-VL 是一款支持中英文等多种语言的视觉语言(Vision Language,VL)模型,相较于此前的 VL 模型,其除了具备基本的图文识别、描述、问答及对话能力之外,还新增了视觉定位、图像中文字理解等能力。Qwen-VL 以Qwen-7B为基座语言模型,在模型架构上引入视觉编码器,使得模型支持视觉信号输入,该模型支持的图像输入分辨率为 448,此前开源的LVLM模型通常仅支持224分辨率。官方表示,该模型可用于知识问答、图像标题生成、图像问答、文档问答、细粒度视觉定位等场景,在主流的多模态任务评测和多模态聊天能力评测中,取得了远超同等规模通用模型的表现。
二、政策梳理
1、上海公布数据要素产业三年发展蓝图 打造国家级数据交易所
【上海市人民政府办公厅发布《立足数字经济新赛道推动数据要素产业创新发展行动方案(2023-2025年)》】8月15日,上海市人民政府办公厅发布《立足数字经济新赛道推动数据要素产业创新发展行动方案(2023-2025年)》,在加强数据产品新供给、激发场景应用新需求、发展数商新业态等七方面采取措施,力争到2025年实现数据要素市场体系基本建成、数据产业规模达5000亿元、引育1000家数商企业等目标;根据《行动方案》,上海将打造“上海数据品牌”,制订品牌建设导则,率先在工业、金融、航运、科创等领域,打造一批具有全国影响力的上海数据品牌。编制数据资源地图,试点建立数据资源统计普查机制,发布数据产品名录。到2025年,形成1000个高质量数据集,打造500家品牌数据企业和1000个品牌数据产品。